Kvantitativní analýza žánrů v díle Karla Čapka1
Miroslav Kubát
Katedra obecné lingvistiky FF UP v Olomouci
<miroslav.kubat@gmail.com>
Abstract:
The paper deals with genre analysis in Czech using quantitative methods, namely frequency structure indicators of text. To avoid any negative influence of authorship on results, the corpus contains only texts written by one author (Karel Čapek). Čapek was selected for his ability to write several genres. Given that all indicators of vocabulary richness are dependent on text length, the texts are divided into chapters and each chapter is reduced to first 400 words. Only mean values of these parts of text can be compared and subsequently used for statistical test. The main aim of this analysis is to discover if choice of genre causes significant changes in style of writing of one author.
Klíčová slova / key words:
kvantitativní lingvistika, žánrová analýza, bohatství textu, stylometrie, korpus, lexikální statistika
1. Úvod
Stylometrie společně s určováním autorství patří k tradičním oblastem kvantitativní lingvistiky. Přestože i v češtině máme několik cenných publikací v této oblasti (např. Těšitelová, Mistrík), užité metody jsou dnes z pohledu tak progresivního oboru, jakým je kvantitativní lingvistika, nutně zastaralé. Tato analýza si klade za cíl zjistit, zda měření bohatství textu je relevantním parametrem pro rozlišování žánrů. Primárně tak nepůjde o nalezení nových poznatků o jednotlivých žánrech, ale spíše o ověření obecných předpokladů kvantitativními metodami.
2. Výběrový soubor
Základem relevantních výsledků každé kvantitativní analýzy je zvolení vhodného výběrového souboru, neboť v lingvistice je nemožné pracovat se základním souborem, tedy všemi realizovanými komunikáty. Vzhledem k tomu, že jde o žánrovou analýzu, bylo třeba eliminovat základní nedostatek podobných výzkumů, a to negativní vliv různých autorských stylů. Je zřejmé, že jednotlivé žánry (ať už je definujeme jakkoliv) tvoří oblasti, které nemají ostré hranice, proto jsou výsledky ovlivněny do značné míry přiřazením jednotlivých textů různých autorů k danému žánru. Z výše uvedených důvodů jsem se rozhodl vytvořit korpus jediného autora, protože pouze taková analýza může generovat změny, které autor provedl na základě vědomí charakteristik jednotlivých žánrů.
Pro analýzu bylo vybráno 28 textů Karla Čapka z 6 různých žánrů. Texty byly segmentovány po jednotlivých kapitolách, pro analýzu pak byly použity průměrné hodnoty. Tímto způsobem bylo dosaženo porovnatelnosti různě dlouhých textů při respektování přirozených hranic uvnitř textu.
3. Metody
Tato analýza je zaměřena na již tradiční oblast kvantitativní lingvistiky, a to zkoumání frekvenční struktury textu. Za posledních 40 let bylo navrženo mnoho nejrůznějších indexů, jež vyjadřují slovní bohatství, opakování slov apod. Souhrnně se této oblasti věnuje především publikace Word frequency studies (Popescu et al., 2009). Přes velké množství různých způsobů pro výpočet bohatství textu je třeba konstatovat, že všechny tyto indexy počítají v podstatě totéž. Proto bude použit jen jeden index frekvenční struktury textu, neboť další indexy by byly zcela redundantní. Vzhledem k tomu, že základním nedostatkem těchto výpočtů je závislost na délce textu, zvolil jsem pro analýzu rovnici pro výpočet frekvenční struktury lambda (Λ) (Popescu et al., 2011), která představuje jeden z posledních pokusů o eliminování vlivu délky textu:
(1) 
(2) 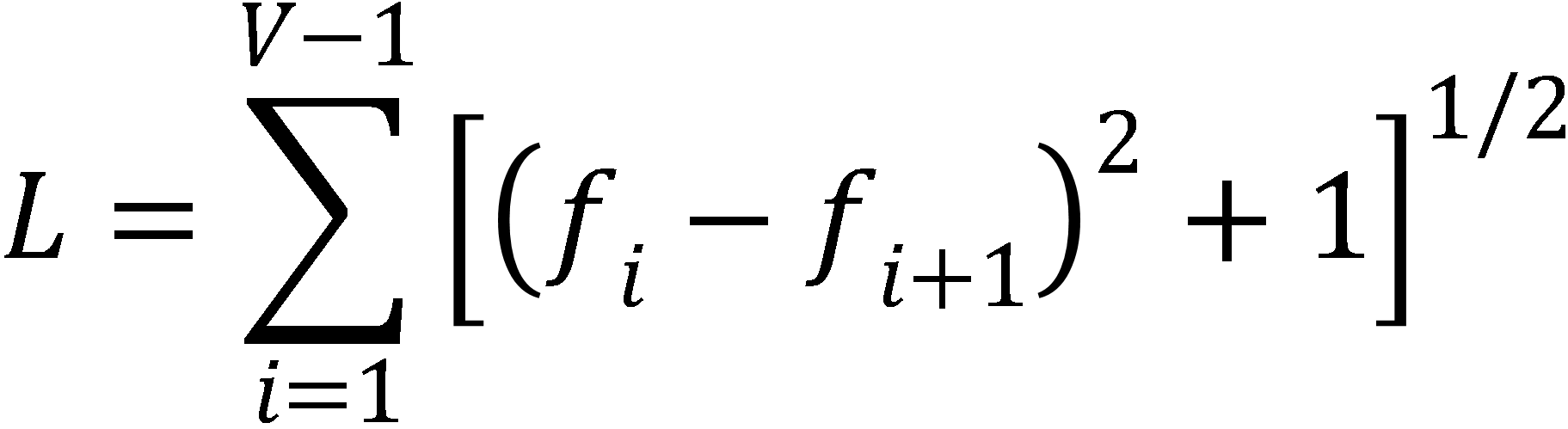
N … délka textu
L ... délka křivky frekvenční distribuce
f
… absolutní frekvence
V
… nejvyšší rank
Pro testování výsledných hodnot byl použit u-test s pravděpodobností 0,05.
(3) 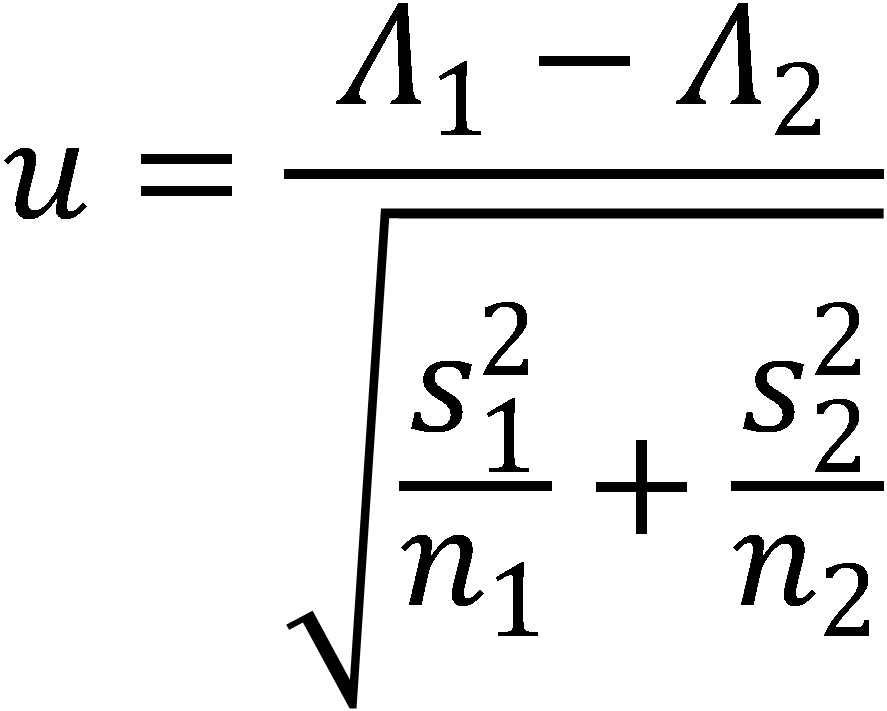
s
… směrodatná odchylka
n
… počet textů
4. Výsledky
Nejdříve byly vypočítány hodnoty lambdy za užití rovnic (1) a (2). Výsledné hodnoty jsou zobrazeny na obr. 1, kde na vodorovné ose je průměrná délka textů N, na svislé ose jsou průměrné hodnoty lambdy.
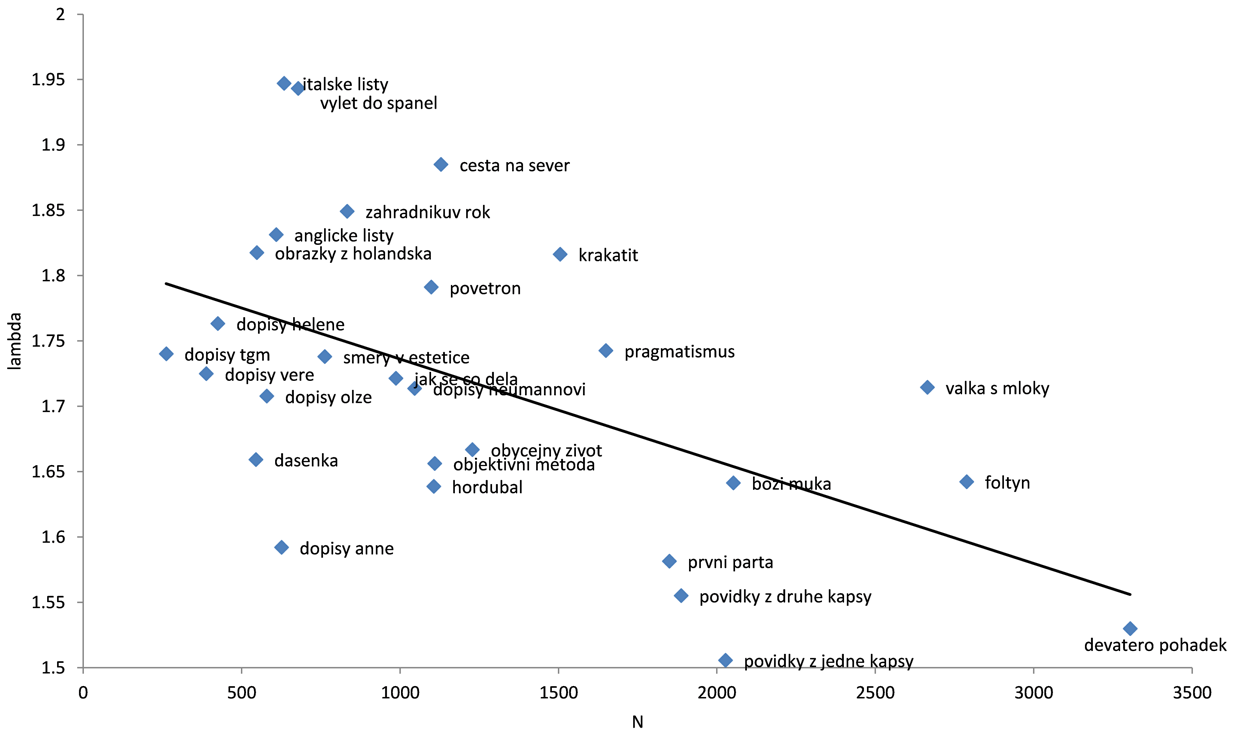
Obr. 1: Průměrné hodnoty lambdy a délky textů N.
Pro lepší vizualizaci jsou na obr. 2 barevně odděleny jednotlivé žánry.

Obr. 2: Průměrné hodnoty lambdy a délky textů N s vyznačením jednotlivých žánrů.
Ačkoliv lze vysledovat z obr. 1 a 2 určité tendence, je zde patrná závislost výsledných hodnot na délce textu. Přestože byla lambda představena jako index nezávislý na délce textu, výsledky svědčí o opaku, a to i přes relativně malé rozdíly mezi délkami. Pro odstranění tohoto problému byly všechny jednotlivé texty (kapitoly) zkráceny na prvních 400 slov. Tímto způsobem byly zachovány přirozené hranice uvnitř textu a zároveň byl eliminován vliv délky textu. Výsledné hodnoty po této úpravě výběrového souboru jsou zobrazeny na obr. 3 (jednotlivé texty) a obr. 4 (jednotlivé žánry).
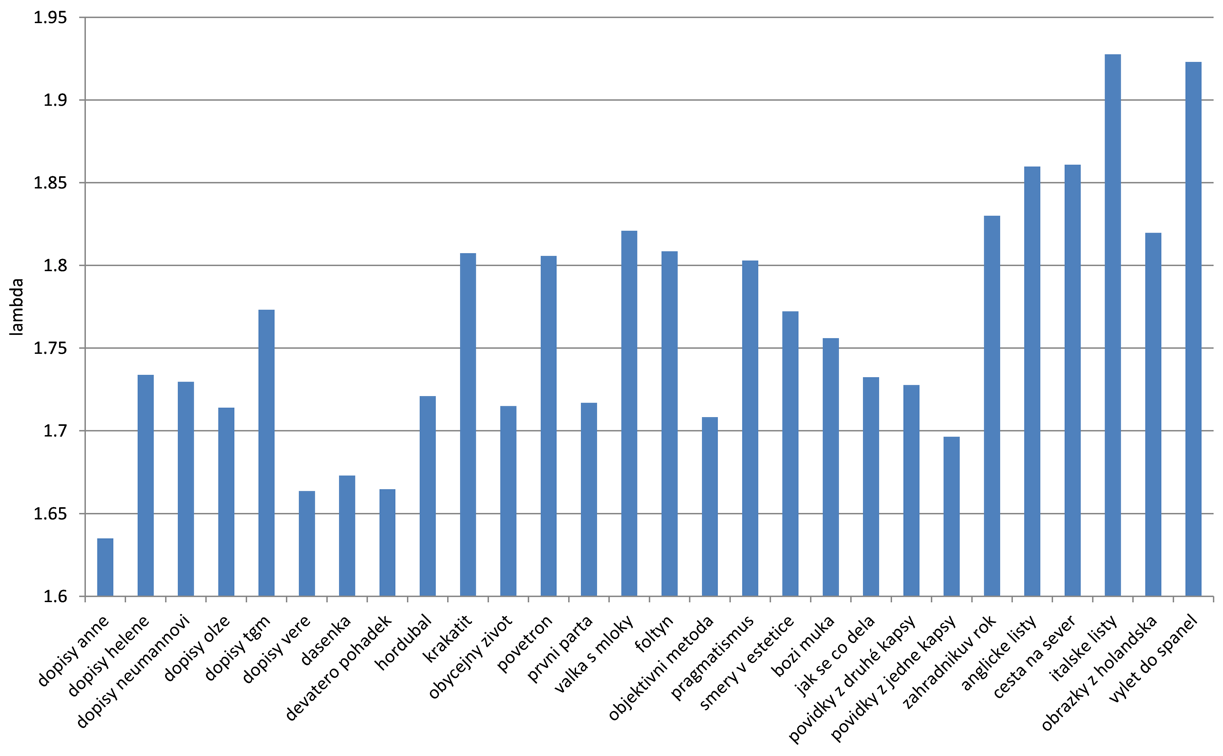
Obr. 3: Průměrné hodnoty lambdy při délce textů 400 slov (texty).

Obr. 4: Průměrné hodnoty lambdy při délce textů 400 slov (žánry).
5. Software QUITA
Pro usnadnění práce s korpusem byl při výpočtech použit software QUITA (Quantitative Index Text Analyzer), který je v současné době vyvíjen na FF UP v Olomouci pod vedením Radka Čecha. Tento nástroj umožňuje jednoduchým způsobem analyzovat texty pomocí kvantitativních charakteristik, jako je slovní bohatství, tematická koncentrace textu, frekvenční struktura atd. Software také umožňuje vytvářet frekvenční seznamy, grafické vizualizace a statistické testování výsledných hodnot. Přestože není tento nástroj ještě dokončen, jeho demoverze je dostupná jako internetová aplikace na internetových stránkách <http://www.lodusweb.net/tk>. Primárním cílem tohoto programu je usnadnit badatelům humanitních oborů práci při kvantitativních analýzách textu.
6. Vyhodnocení
Přestože jsou z obr. 4 patrné jisté rozdíly mezi jednotlivými žánry, bylo třeba provést statistický test těchto rozdílů za užití rovnice (3). Výsledky testu jsou zobrazeny v tab. 1, kde u ≥ 1,96 značí signifikantní rozdíl, pro přehlednost jsou signifikantní rozdíly vyznačeny tučně.
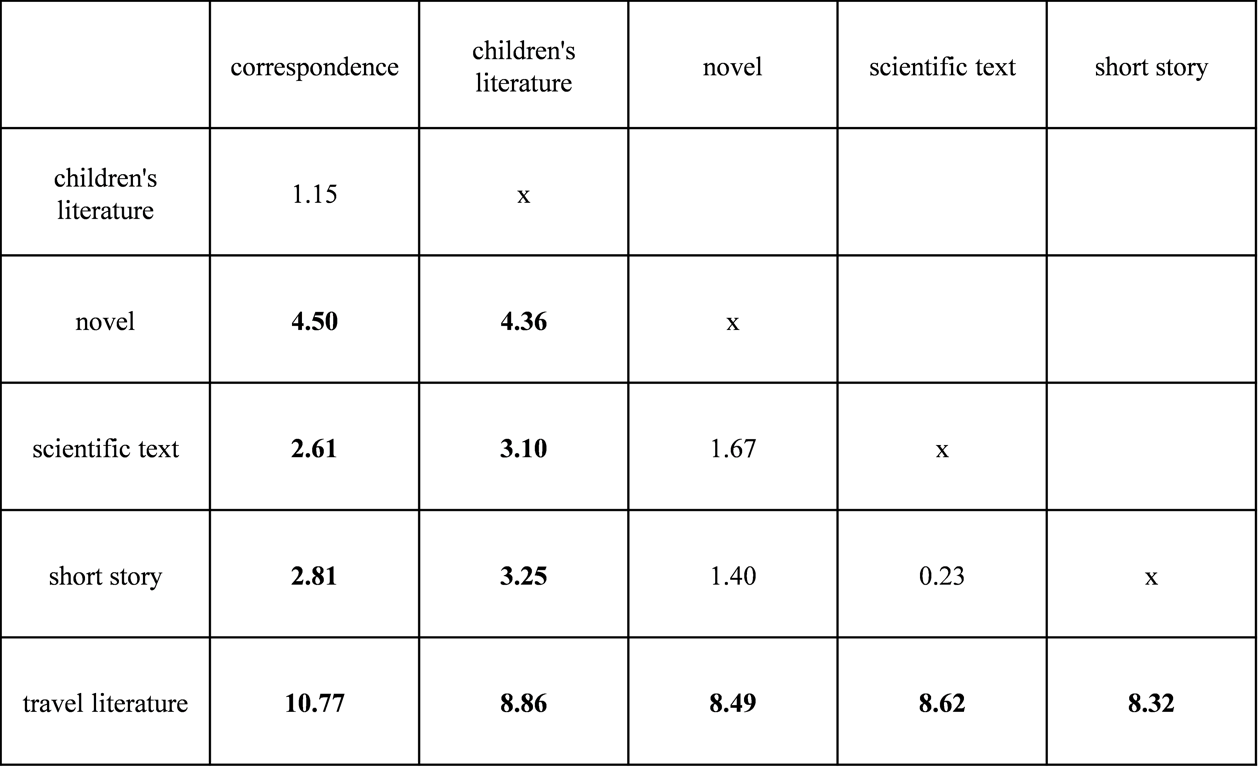
Tab. 1: Výsledky u-testu (u ≥ 1,96 značí signifikantní rozdíl).
Z výsledků je patrné, že v oblasti bohatství slovníku zaujímají specifické místo korespondence, dětská literatura a cestopisy. Zatímco v osobní korespondenci chudší lexikum odpovídá značné neformálnosti této komunikace, v případě literatury pro děti je můžeme přičíst zejména zaměřením na specifického adresáta. Bohatý slovník cestopisů pak odkazuje k užívání mnohých místních jmen, popř. cizích slov.
7. Závěr
Na základě výsledných hodnot lambdy a následného statistického testování jejich rozdílů lze konstatovat, že bohatství textu je relevantní charakteristika pro rozlišení žánrů. Z toho vyplývá, že Karel Čapek musel při psaní zkoumaných textů vědomě svůj styl ve sledovaném parametru přizpůsobit požadavkům jednotlivých žánrů. Dále je třeba uvést, že dlouhodobá snaha kvantitativních lingvistů o eliminování vlivu délky textu na výpočty bohatství textu se zdá být nedosažitelná. Ukazuje se, že jakákoliv normalizace slouží pouze k částečnému zmírnění uvedeného vlivu, proto je nutné hledat řešení spíše v segmentaci výběrového souboru. Pouze vhodně zpracovaný korpus, který respektuje přirozené hranice uvnitř textu a zároveň zajistí porovnatelně dlouhé texty, může generovat relevantní výsledky v oblasti měření bohatství textu.
Literatura:
Čech, Radek (2011): Frequency structure of New Year’s presidential speeches in Czech: the authorship analysis. In: Emmerich Kelih et al. (eds.), Issues in Quantitative Linguistics 2. Lüdenscheid: RAM-Verlag, s. 82–94.
Popescu, Ioan-Iovitz et al. (2009): Word Frequency Studies. Berlin – New York, NY: Mouton de Gruyter.
Popescu, Ioan-Iovitz – Altmann, Gabriel (2006): Some aspects of word frequencies. Glottometrics, 13, s. 23–46.
Popescu, Ioan-Iovitz – Altmann, Gabriel – Čech, Radek (2011): The Lambda-Structure of Texts. Lüdenscheid: RAM-Verlag.
Popescu, Ioan-Iovitz – Mačutek, Ján – Altmann, Gabriel (2009): Aspects of Word Frequencies. Lüdenscheid: RAM-Verlag.
Internetové odkazy:
Quantitative Index Text Analyzer. Demoverze. Dostupné z WWW: <http://www.lodusweb.net/tk>.
Poznámka
1 Výzkum prezentovaný v této práci vznikl v rámci projektu QUITA (Quantitative Index Text Analyzer) – Software pro měření indexů slovního bohatství a jiných kvantitativních charakteristik textu (FF_2013_031) financovaný studentskou grantovou soutěží Univerzity Palackého v Olomouci.